Pod
Kubernetes给我们提供了多种部署Pod的方式,主要分为两种:
- 自主式
Pod:即在yaml中指定Kind=Pod的方式。 - 控制器管理
Pod:Kubernetes内置了多种控制器管理Pod,例如Replication Controller,我们可以直接指定Kind=Replication Controller即可,我们可以设定副本数=1,那么Kubernets会自动创建/删除Pod维持我们的期望Pod数目。下图所示了Kubernetes常用的控制器。
创建第一个Pod
该
Pod中包含两个容器:Tomcat和Nginx* 编写资源清单
1 | # vim pod.yaml |
运行 kubectl apply -f pod.yaml,查看运行状态kubectl get pod,验证Pod中包含的容器docker ps
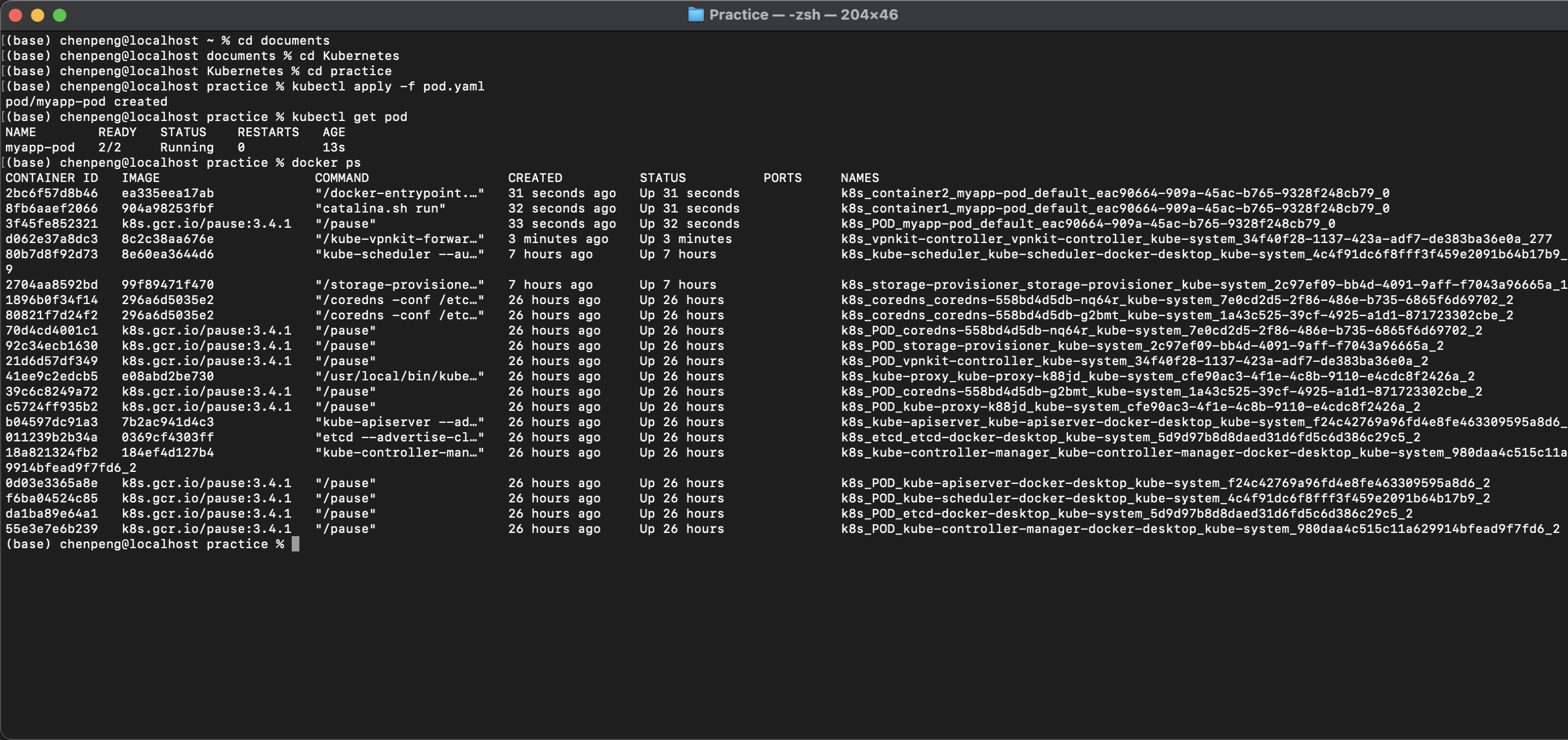
第一个Pod创建完成,如果这个时候,该Pod所在的节点宕机了,即该Pod被杀死了。
kubectl delete pod myapp-pod
kubectl get pod
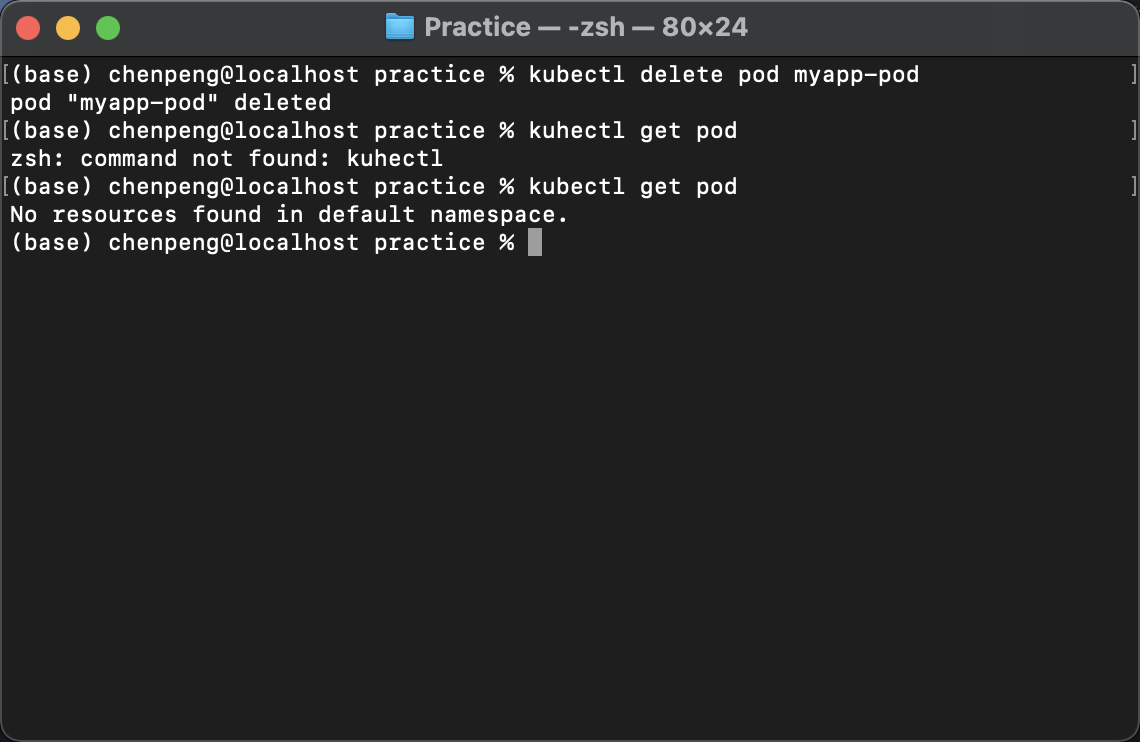
我们发现我们创建的Pod没有了,但是有时候我们的想法是这个样子的:给我部署一个Tamcat服务器,如果该Tomcat挂掉了,自动重新启动一个,这个时候怎么办呢?这个时候就引出了控制器管理Pod
Replication Controller
Replication Controller(RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来代替;而异常多出来的容器也会自动回收。所以RC的定义包含以下几个部分:
Pod期待的数目(replicas)。- 用户筛选目标
Pod的Label Selector。
Label即标签的意思,可以附加到各种资源上,例如Node、Pod、Rc、Serice等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源上去。随后可以通过Label Selector(标签选择器)查询和筛选有某些Label的资源对象。 不同控制器内部就是通过Label Selector来筛选要监控的Pod,例如RC通过Label Selector来选择要监控Pod的副本数。所以我们在编写不同的控制器的时候一般都需要配置Label Selector。 * 当Pod的副本数小于预期数目的时候,用户创建新的Pod的模板(template)
创建第一个Replication Controller
Pod包含一个容器Tomcat,Pod通过RC控制器管理,维持副本数为3 * 编写资源清单
1 | # vim rc.yaml |
需要注意的是
spec.template.metadata.labels指定了该Pod的标签,这里的标签需要和spec.selector相匹配,否则此RC每次创建一个无法匹配的Label的Pod,就会不断地尝试创建新的Pod,最终陷入“只为他人做嫁衣“的悲惨世界中,永无翻身之时。
运行文件创建rckubectl apply -f rc.yaml,查看rc的运行状态kubectl get rc,查看pod的运行状态kubectl get pod,可以发现,rc时刻向3个pod同时在运行的状态移动,直到三个pod都处于running状态。
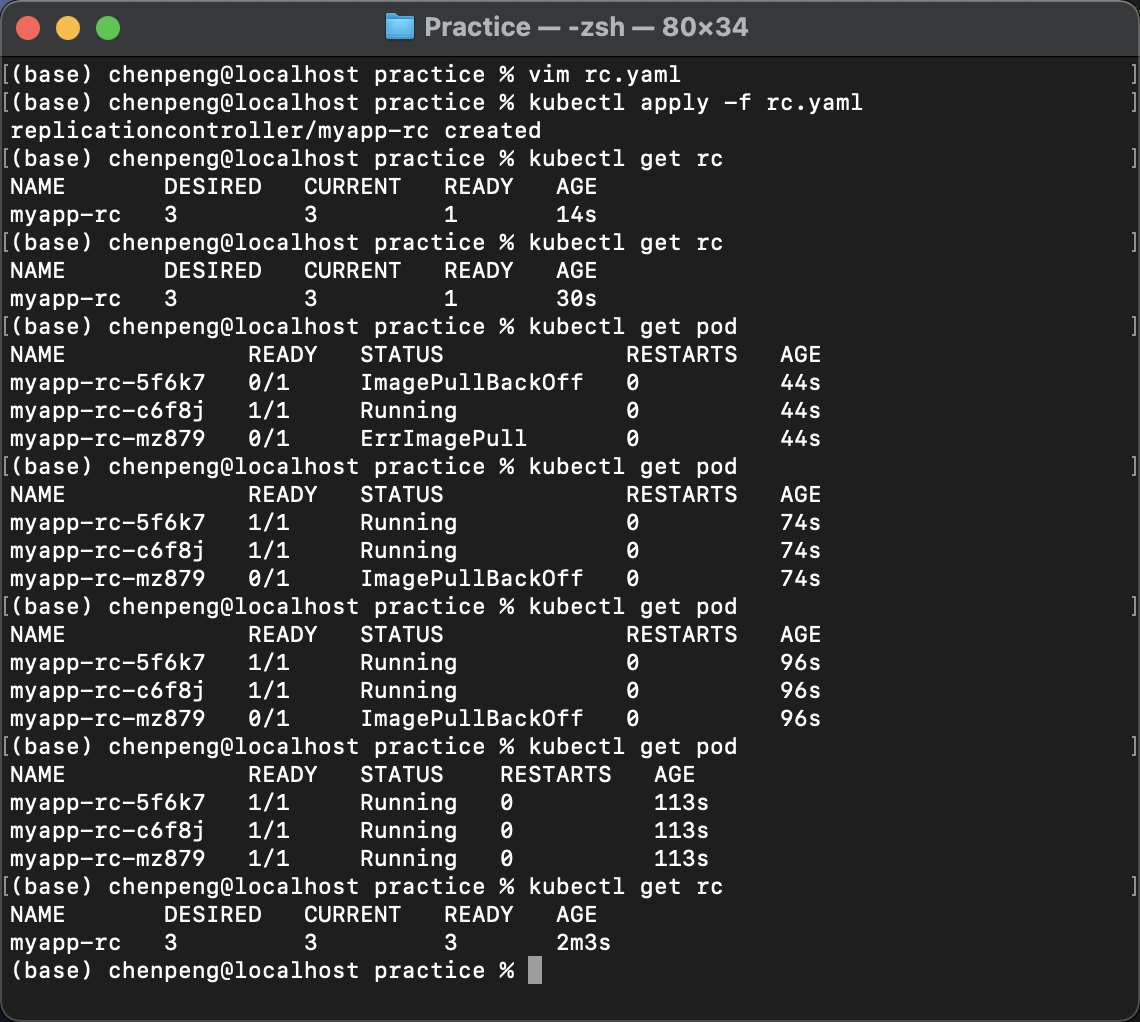
删除名为myapp-rc-c6f8j的Pod,验证RC时候是否会自动创建新的Pod
kubectl delete pod myapp-rc-c6f8j
kubectl get pod
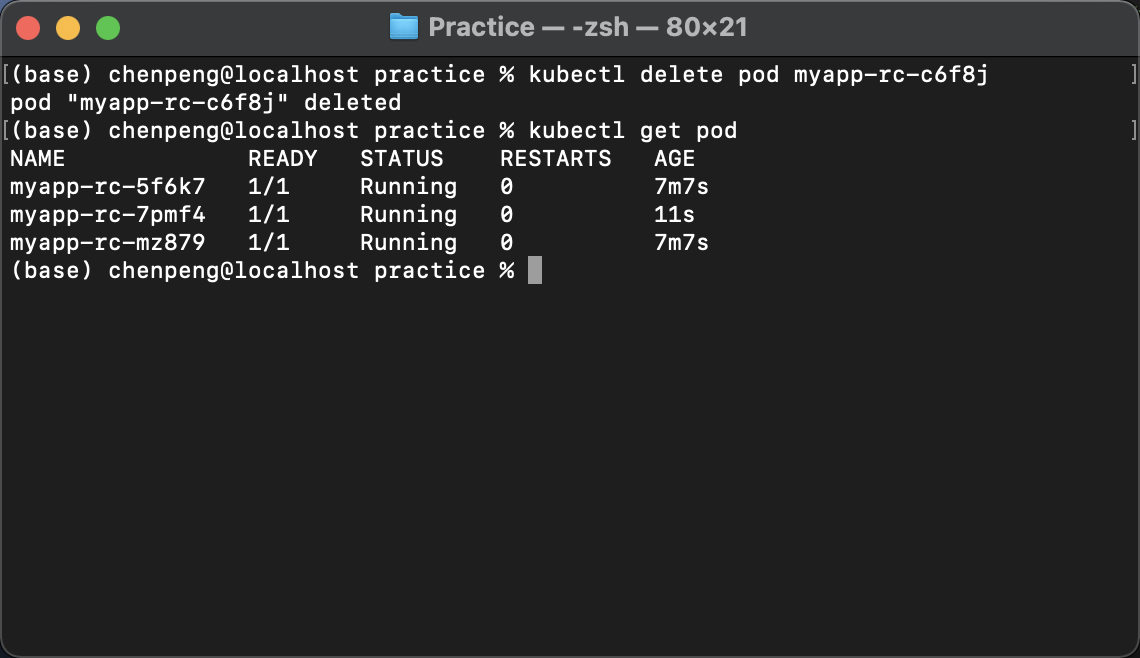
我们发现rc自动创建了一个新的pod,名为myapp-rc-7pmf4
将名为myapp-rc-5f6k7的Pod的Label重命名为label_2_key=label_2_value
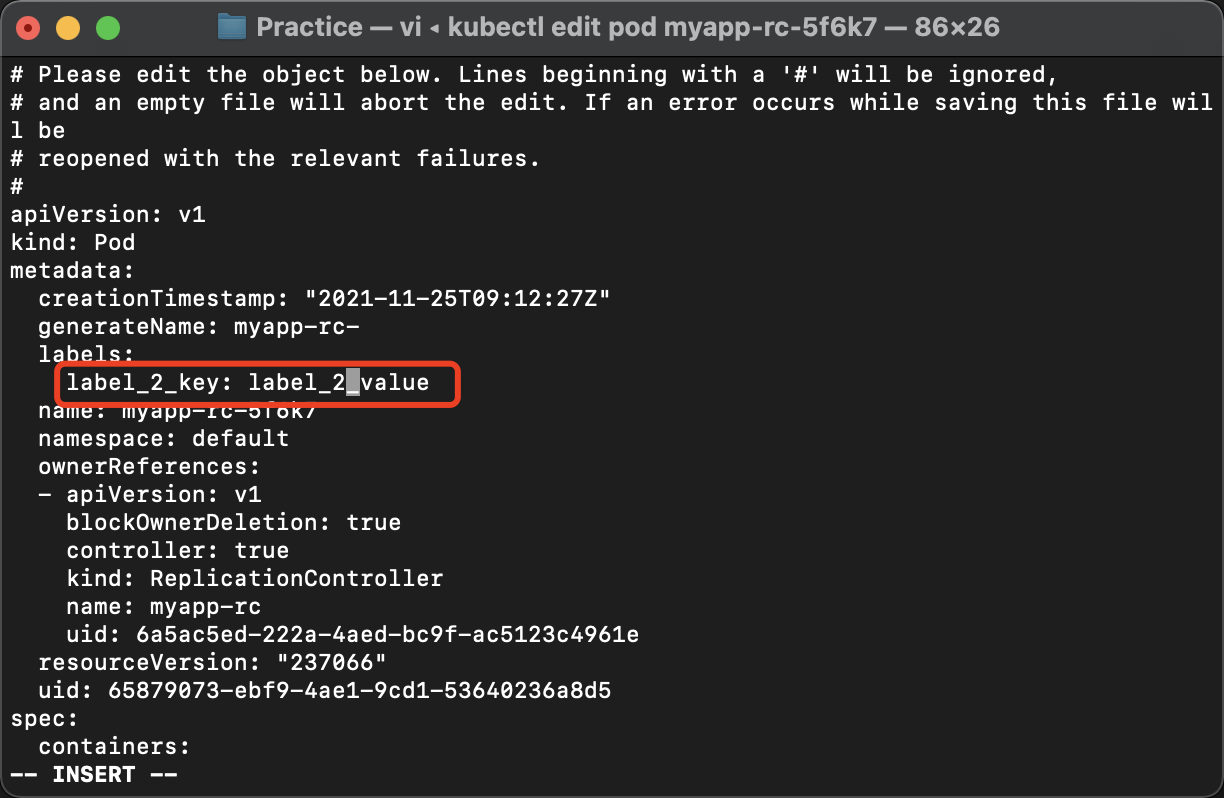
再次查看rc的和pod的状态:
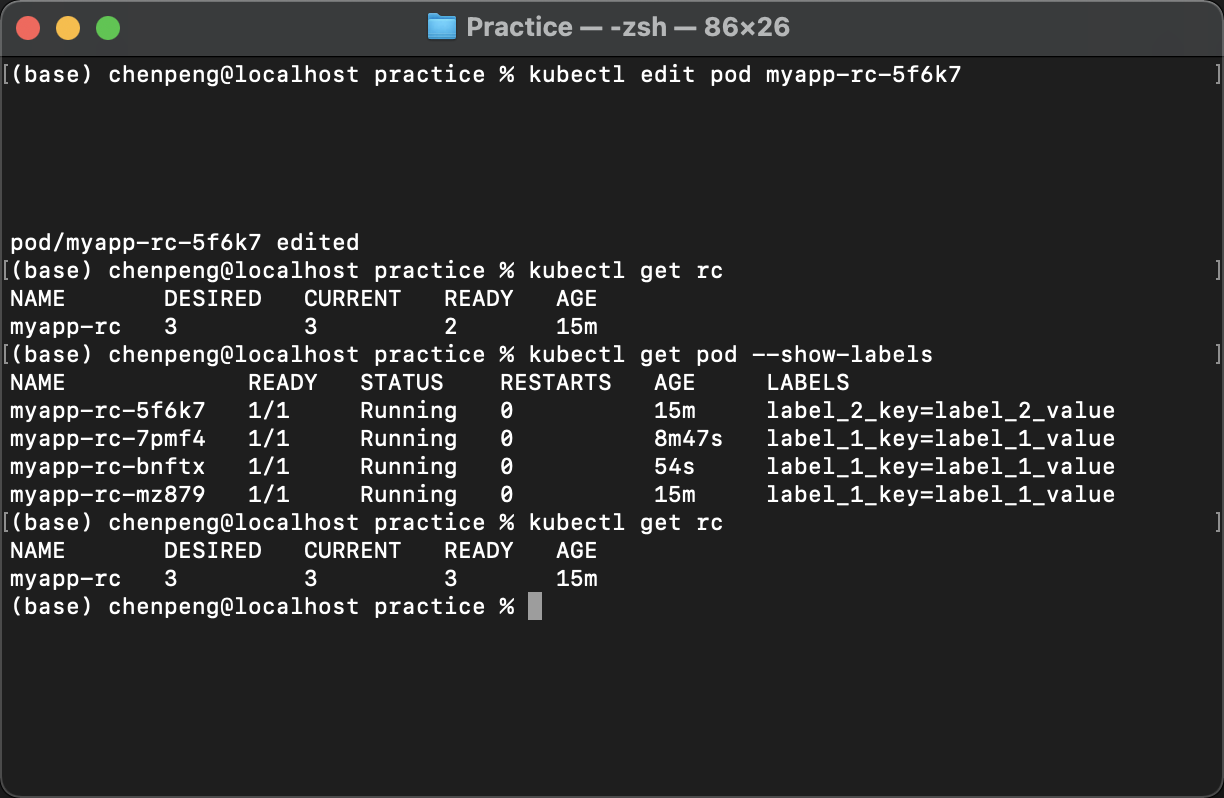
由于myapp-rc-5f6k7标签修改,导致该Pod不受RC管理,所以RC为了维持副本数为3,为我们重新创建了一个新的Pod
Replication Set
Replication Set(RS)跟Replication Controller没有本质的不同,只是名字不一样,并且Replication Set支持集合式的selector。
RS的定义与RC的定义很类似,除了API和Kind类型有所区别:
1 | apiVersion: extensions/v1beat1 |
Deployment
Deployment为Pod和RS提供了一个声明时定义方法,用来替代以前RC来方便的管理应用,其提供了Pod的滚动升级和回滚特性,主要应用场景包括。
- 定义
Deployment来创建Pod和RS。 - 回滚升级和回滚应用。
- 扩容和缩容。
- 暂停和继续
Deployment。
Deployment的定义与RS的定义很类似,除了API和Kind类型有所区别:
1 | apiVersion: extensions/v1beta1 |
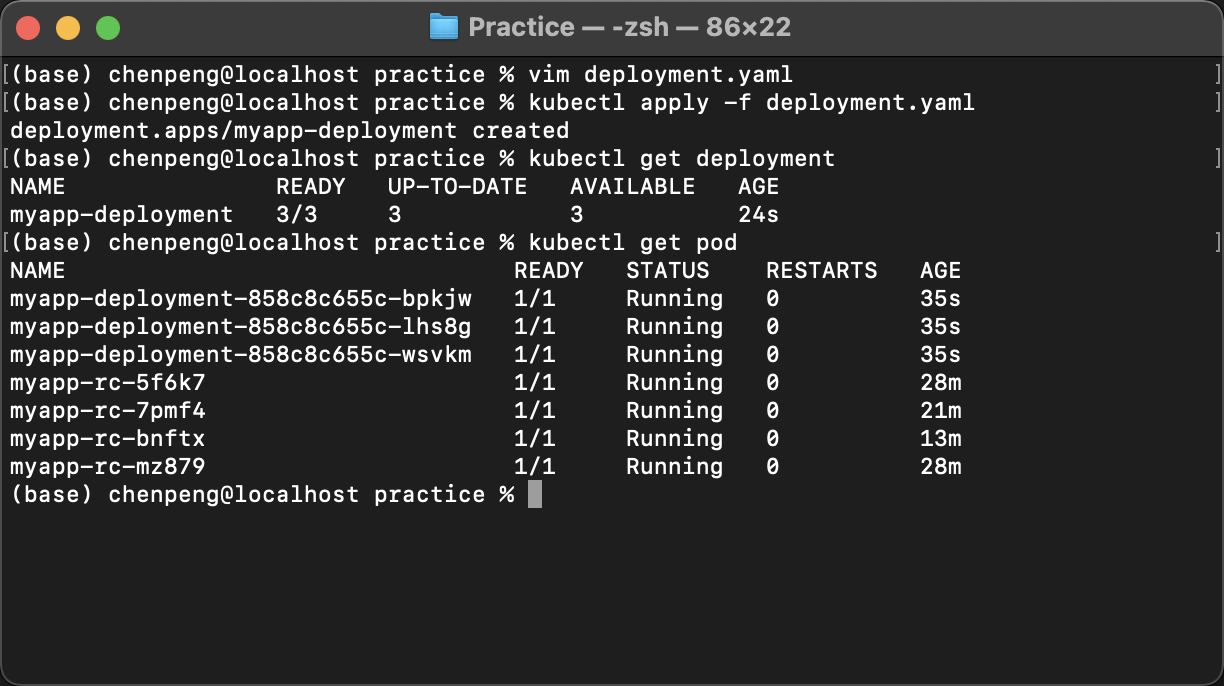
创建第一个deployment
- 编写资源清单
1 | # vim deployment.yaml |
- 运行并查看运行状态
kubectl apply -f deployment.yaml
kubectl get deployment
kubectl get pod
Horizontal Pod Autoscaling
Horizontal Pod Authscaler简成HPA,意思是Pod自动横向扩容,它也是一种资源对象。通过追踪分析所有控制Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理。这里不做深究,附HPA的api资源清单:
1 | # vim hpa.yaml |
StatefullSet
StatefullSet是为了解决有状态服务的问题(对应Deployment和RS是为无状态服务而设计)
DaemonSet
DaemonSet确保全部(或者一些)Node上运行一个Pod副本。当有Node加入集群时,也会为它们创建一个新的Pod。当有Node从集群中移除的时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
Job
Job负责批处理任务,即仅执行一次的任务,它确保批处理任务的一个或者多个Pod成功运行。
Service
简单来说,外部客户端是无法直接访问Pod的,必须通过Service,Service将这些服务暴露给内部或外部的客户端,那么客户端就可以通过Ip+Port的方式访问至我们的多个Pod。为什么说是多个Pod呢?因为Service为我们提供了复杂均衡机制。例如我们通过Deployment部署了一个Tomcat,replicas设置为3,Service提供了多种负载均衡策略,针对不同的请求路由到不同的Pod上。
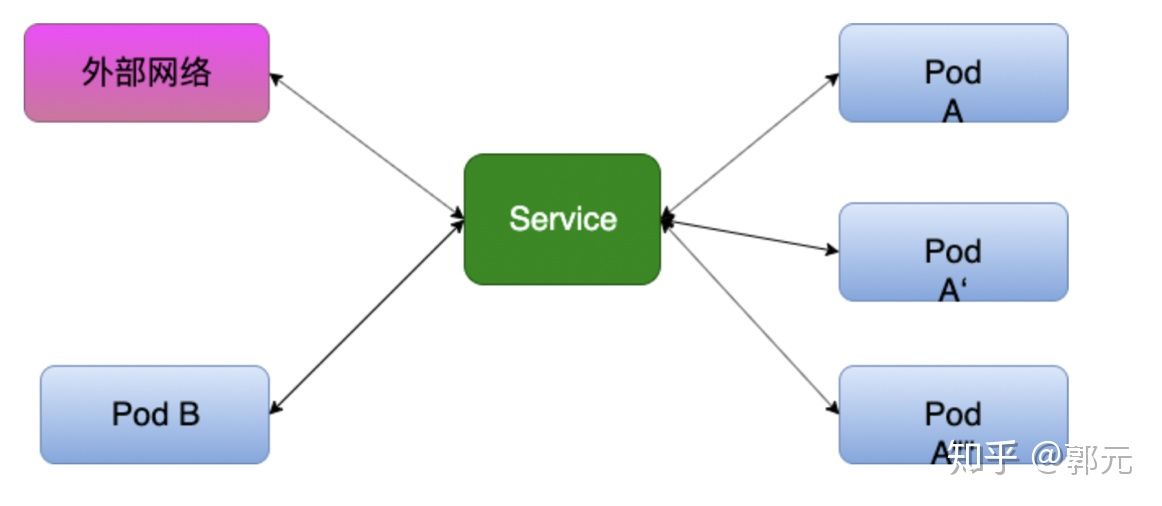
采用微服务架构时,作为服务所有者,除了实现业务逻辑外,我们也需要考虑应该怎样发布我们的服务,例如发布的服务中哪些服务不需要暴露给客户端,仅仅在服务内部之间使用,哪些服务我们又需要暴露出去,这就涉及到三种服务方式:ClusterIp、NodePort、LoadBalancer
ClusterIP
当我们发布服务的时候,Kubernetes会为我们的服务默认分配一个虚拟的IP,即ClusterIp,这也是Service默认的类型。
创建一个ClusterIP
通过
Deployment部署一个Tomcat,replcas设置为3,并通过ClusterIP的方式注册tomcat为Service,另外我们创建一个Nginx Pod,通过Nginx Pod测试是否能访问该服务,另外我们通过本机是否能Ping通该服务
创建
Tomcat Service1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# vim myapp-deploy-tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-tomcat
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp-tomcat
template:
metadata:
labels:
app: myapp-tomcat
spec:
containers:
- name: myapp-tomcat
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: myapp-service-tomcat
namespace: default
spec:
type: ClusterIP
selector:
app: myapp-tomcat
ports:
- name: http
port: 8080
targetPort: 8080创建
Pod1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# vim myapp-pod-tomca.yaml
# 我们使用k8s哪个版本的api
apiVersion: v1
# 声明我们要创建一个Pod
kind: Pod
# 设置以下Pod中包含的元数据信息
metadata:
name: myapp-pod-tomcat
# 设置该Pod特有的东西
spec:
# 设置容器
containers:
- name: myapp-pop-tomcat
image: tomcat
imagePullPolicy: IfNotPresentPod中访问Servicekubectl get podkubectl get svckubectl exec myapp-pod-tomcat -it -- /bin/bashcurl 10.103.250.70:8080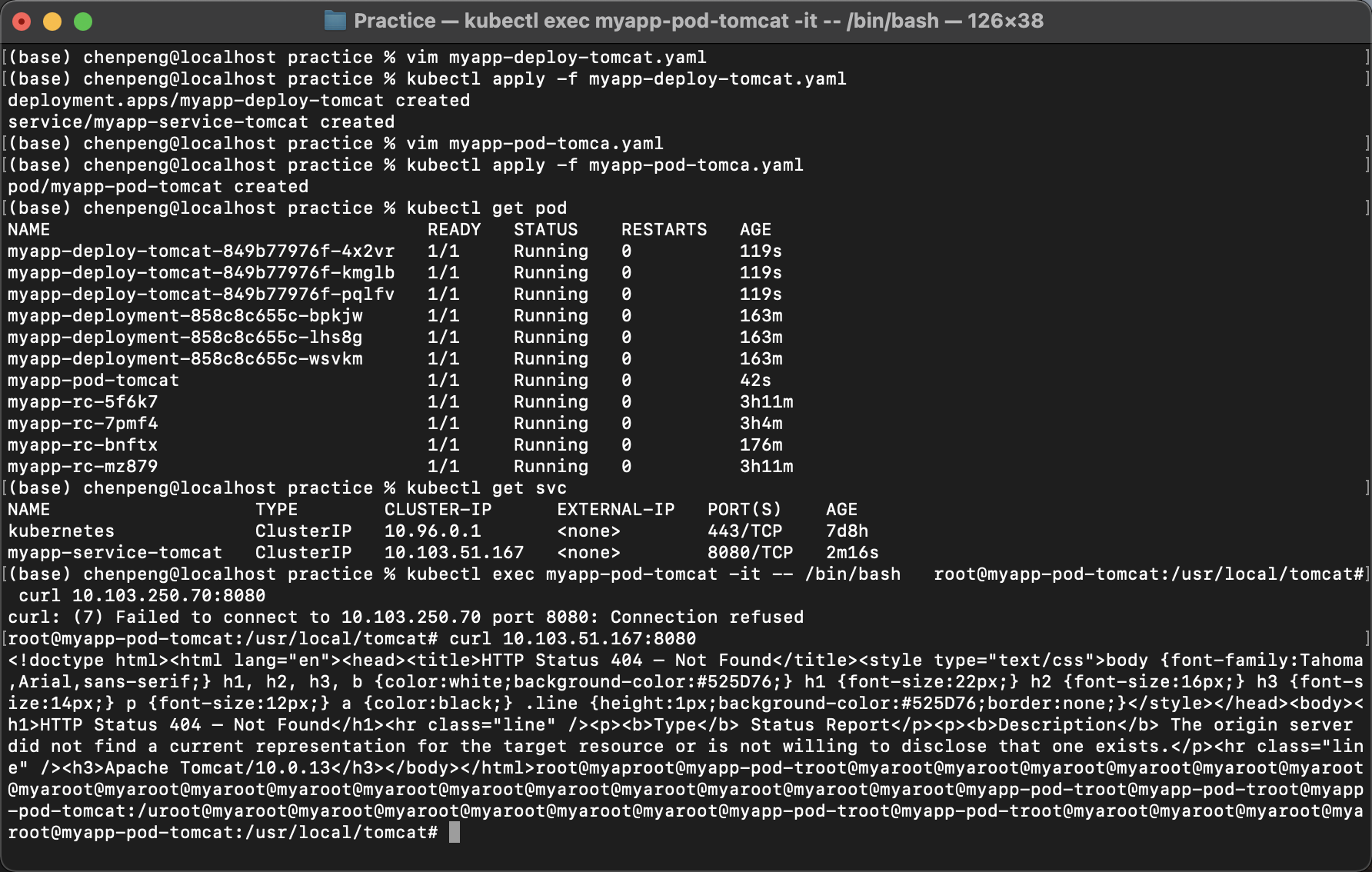
本机访问
Tomcat Servicecurl localhost:8080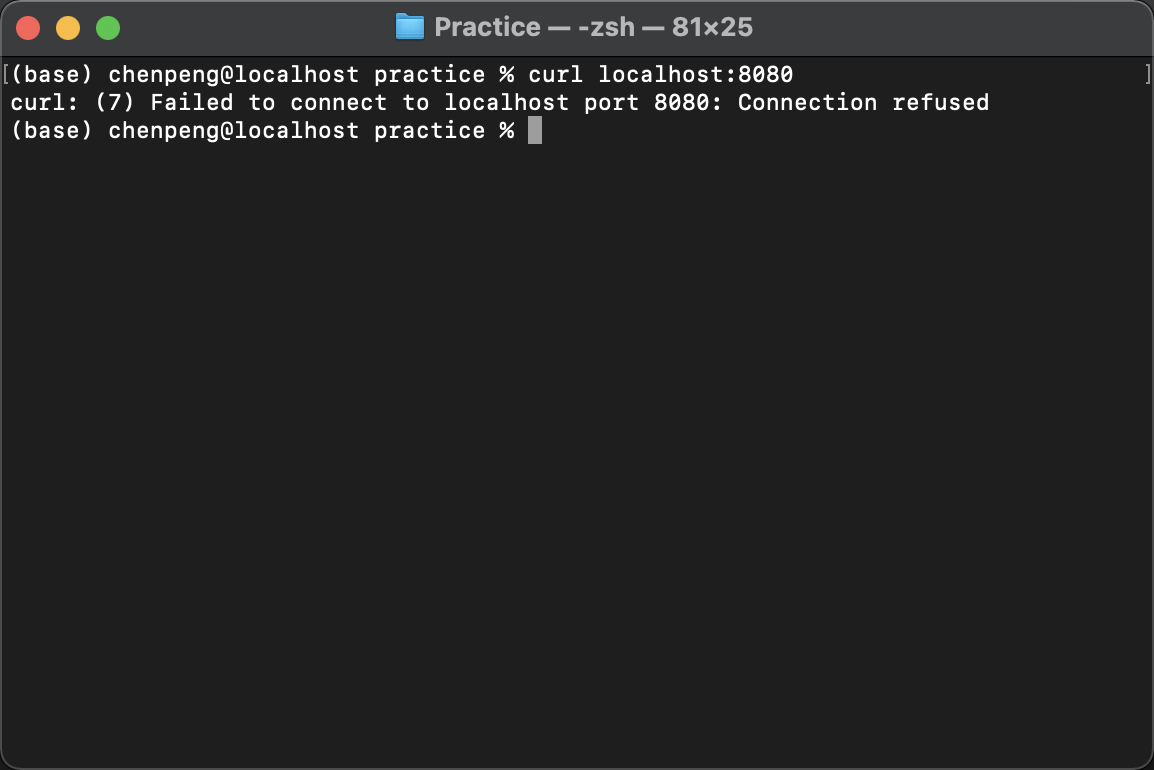
NodePort
根据上述的分析和总结,我们基本明白了:Service的Cluster IP属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾来了,实际上我们开发的许多业务中肯定有一部分服务是要提供给Kubernetes集群外部的应用或者用户来访问的,典型的就是Web端的服务模块,比如上面的tomcat-server,因此我们在发布Service的时候,可以采用NodePort的方式。
创建第一个NodePort
NodePort的实现方式是在Kubernetes集群中的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只要使用任意一个Node的Ip+具体的NodePort端口号即可访问此服务。
创建
Tomcat Service1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# vim myapp-node-port-tomcat.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-tomcat
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp-tomcat
template:
metadata:
labels:
app: myapp-tomcat
spec:
containers:
- name: myapp-tomcat
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: myapp-service-tomcat
namespace: default
spec:
type: NodePort
selector:
app: myapp-tomcat
ports:
- name: http
port: 8080
targetPort: 8080本地测试
kubectl get svccurl localhost:32027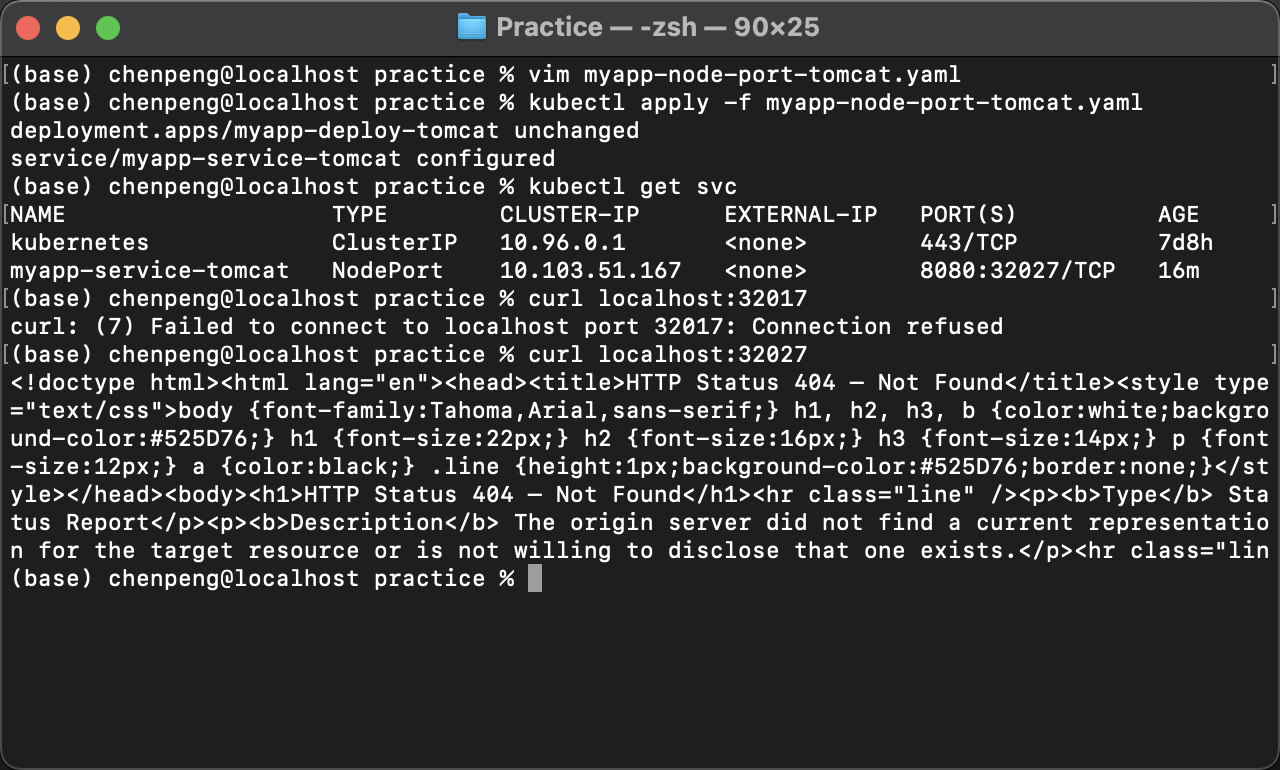
LoadBalancer
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,由负载均衡器负责转发流量到后面某个Node的NodePort上,LoadBalancer就起这个负载均衡器的作用。
如果我们的集群运行在谷歌的GCE公有云上,那么我们只要把Service的type=NodePort改成Node=LoadBalancer,此时Kubernetes会自动创建一个对应的Load Balancer实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到上述目的。这里不对此对象进行研究。
下周我们将继续研究Kubernetes的存储对象。
参考文件:知乎:一起学习k8s